
Featured Data Variable: “Branch Count”
The “Branch Count” variable doesn’t appear on standard business data supplies, because more questions would be raised than answered. Yet it’s a very powerful selection filter. The branch count field has a numerical value, relating to the number of sites per company.
Examples
Some examples of high branch count businesses by their respective industry sector;
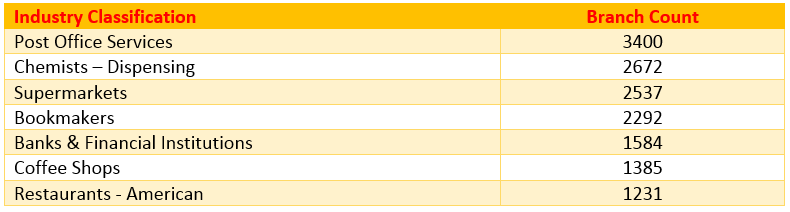
With perhaps the exception of the post offices (which tend to be semi-independent), these 15,000 business records represent just seven companies. And it doesn’t take a genius to work out which specific companies they are.
Taking the dispensing chemist by way of example. Having 2,672 branches means they are on every high street. Would you want to market your business to each of these at a branch level? There is virtually no branch-level autonomy, so the answer is almost certainly no.
Branch Count – Beware!
One of the shameful elements of the data industry is that (in being financially rewarded for supplying the largest possible data volume to clients), unfortunately there is an ‘incentive’ for these records to be included within your file. Personally I would regard this as short-termism, as the data quality will be massively diluted and usually lead to client dissatisfaction.
It genuinely saddens me to audit client databases sourced from another supplier where the file is heavily peppered with certain American (fast food) restaurants or ‘big four’ supermarkets. And I have no qualms in stating that their database (if diluted to an unacceptable level) is unfit for purpose. Good data suppliers should apply a duty of care in filtering out unsuitable prospects.
Whilst filtering can never be perfect, there are some basics which should be applied as standard. Unless requested otherwise, high branch count records are automatically recommended for exclusion by Responsiva.
How Is the Information Evaluated?
The branch count field is not a perfect value. It is evaluated by applying some intelligence to company name matching. And there are some anomalies. As a general rule, the likes of matching “M&S” with “Marks & Spencer” will be fine. And there is also some intelligence in segmenting company names such as “Red Lion” or “Taj Mahal”; which to the human eye will all be independent entities.
But where the branch count gets it seriously wrong is with hotels. By way of a fabricated example, matching “London Hilton Park Lane Metropol” with “Hilton Picadilly Manchester” is not realistic. So the branch count for hotels tends to be blank, and this is one sector where chains can slip through the net.
Head Offices?
Often I am asked if the head offices of businesses are identifiable. The reality is that they aren’t; many companies use their accounting and auditing firms (or a PO Box address) by way of their Companies House registration, so matching to this file is not the right way forward. Quite simply it is not worth the risk of including every branch within your database, so the high branch count records are usually best excluded as standard.
Whilst head offices are impossible to accurately identify, they can be implied. This can work well with companies having 10 – 20 branches. The best way of achieving this is in selecting data where there is also a director level contact name at site. Most multi-premise businesses would only have managerial contact name (e.g. Branch manager) at each site.
So the records with a director level name will generally have at the very least some autonomous decision-making capability.